#
KoboldCpp
KoboldCppはGGMLおよびGGUFモデル用の自己完結型APIです。
NyxによるこのVRAM Calculatorは、モデルが必要とするおおよそのRAM/VRAMを教えてくれます。
#
Nvidia GPU Quickstart
このガイドはWindowsを使用していることを前提としています。
- 最新リリースをダウンロード: https://github.com/LostRuins/koboldcpp/releases
- KoboldCppを起動します。Microsoft Defenderからのポップアップが表示される場合がありますが、
Run Anywayをクリックしてください。 - バージョン1.58以降、KoboldCppは次のようになっているはずです:
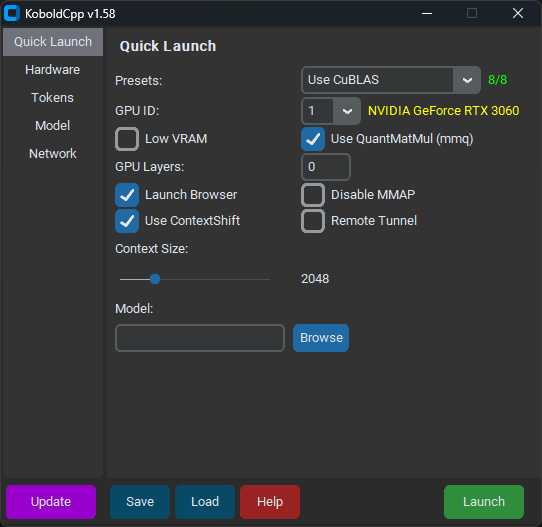
Quick Launchタブで、モデルと希望するContext Sizeを選択します。Use CuBLASを選択し、GPU IDの横の黄色のテキストがGPUと一致していることを確認します。- 低VRAMでも
Low VRAMにチェックを入れないでください。 - Nvidia 10シリーズ以前のGPUを持っていない限り、
Use QuantMatMul (mmq)のチェックを外してください。 GPU Layersはモデルをロードしたときに自動入力されているはずです。今はそのままにしておいてください。Hardwareタブで、High Priorityにチェックを入れます。Saveをクリックして、毎回の起動時にKoboldCppを設定する必要がないようにします。Launchをクリックしてモデルがロードされるのを待ちます。
次のようなものが表示されるはずです:
Load Model OK: True
Embedded Kobold Lite loaded.
Starting Kobold API on port 5001 at http://localhost:5001/api/
Starting OpenAI Compatible API on port 5001 at http://localhost:5001/v1/
======
Please connect to custom endpoint at http://localhost:5001これでSillyTavern内でKoboldCppにhttp://localhost:5001をAPI URLとして接続してチャットを開始できます。
おめでとうございます!完了です!
ある意味では。
#
GPU Layers
KoboldCppは動作していますが、できるだけ多くのレイヤーをGPUにオフロードすることでパフォーマンスを向上させることができます。ターミナルで次のようなものが表示されるはずです:
llm_load_tensors: offloading 9 repeating layers to GPU
llm_load_tensors: offloaded 9/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 7043.34 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1479.19 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 578.81 MiB数字を恐れないでください。この部分は見た目ほど難しくありません。CPU buffer sizeは使用されているシステムRAMの量を指します。これは無視してください。CUDA0 buffer sizeは使用されているGPU VRAMの量を指します。CUDA_Host KV buffer sizeとCUDA0 KV buffer sizeは、モデルのコンテキストに専用されているGPU VRAMの量を指します。この場合、KoboldCppは約9 GBのVRAMを使用しています。
私は12 GBのVRAMを持っており、コンテキストに2 GBのVRAMしか使用されていないため、モデルをロードするために約10 GBのVRAMが残っています。9レイヤーが約7 GBのVRAMを使用し、7000 / 9 = 777.77なので、各レイヤーが約777.77 MIBのVRAMを使用すると仮定できます。10,000 MIB / 777.77 = 12.8なので、切り捨てて今後このモデルでは12レイヤーをロードします。
モデル、コンテキストサイズ、システムのVRAMを使用して独自の計算を行い、KoboldCppを再起動します:
- 以前に
Saveをクリックした場合は、Loadを使用して以前の設定をロードできます。それ以外の場合は、以前に選択したのと同じ設定を選択します。 GPU Layersを新しいVRAM最適化された数値(私の場合は12レイヤー)に変更します。Saveをクリックして更新された設定を保存します。
次のようなものが表示されるはずです:
llm_load_tensors: offloading 12 repeating layers to GPU
llm_load_tensors: offloaded 12/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 9391.12 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1286.25 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 771.75 MiBKoboldCppは12 GBのVRAMのうち約11.5 GBを使用しています。これは、KoboldCppが自動的に生成した設定よりもはるかに優れたパフォーマンスを発揮するはずです。
おめでとうございます!(実際に)完了です!
KoboldCpp設定のより詳細な説明については、KalomazeのSimple Llama + SillyTavern Setup Guideをご覧ください。