#
話す
SillyTavern 1.12.13でのサポートがドロップされました。このページは歴史的理由で保持されます。
#
それは何ですか?
AITuberのための Talking Head Anime 3デモの実装です。それは次の機能を持っています:
- 単一の静止画像からランダムなLive 2Dのようなモーション アクションを生成。
- すべてのTTS出力からの音声出力に唇同期。
この拡張機能には、Talking Head(?)アニメから単一の画像の3:Now the Body Tooプロジェクトの元のデモプログラムが含まれています。名前が示すように、プロジェクトはアニメキャラをアニメーション化でき、このためには単一の画像のみが必要です。2つのデモプログラム:
Manual_poserは、グラフィカル ユーザー インターフェースを通じてキャラクターの表情、頭部回転、体回転、およぼれる呼吸に対する胸の拡大を操作できます。Happy、Sad、Joy等のデフォルト式として保存できます。 ifacialmocap_puppeteerは、アニメキャラにお顔面のモーションを転送します。
#
ハードウェア要件
CPUまたはGPU モードのいずれかを使用できます(デフォルトはCPU)。ただし、CPUモードでは約1フレーム/秒と、GPUモードではRTX3060で約9~10フレーム/秒を得られることを期待します。
ifacialmocap_puppeteerはビデオフィード から blend shape パラメータを計算できるiOSデバイスが必要。つまり、デバイスはiOS 11.0以上を実行でき、TrueDepthフロントカメラが必要(詳細についてはこのページを参照)。言い換えれば、iPhone X またはそれ以降を持っている場合、セットアップされます。
#
使用方法
extrasをclassifyとtalkingheadモジュールで起動する必要があります!
classifyはtalkinghead.pngファイルの処理に必要です。さらに、--talkinghead-gpuを使用してブレンド モデルをGPUメモリーに読み込み、アニメーション10倍高速化できます。GPUアクセラレーション強く推奨!デフォルトでは、プログラムが開始されるとデフォルト イメージSillyTavern-extras\talkinghead\tha3\images\lambda_00.pngを読み込みます。http://localhost:5100/api/talkinghead/result_feedまたはYOUR EXT URL:PORT/api/talkinghead/result_feedに移動して動作確認。
サーバー開始後、Extension APIタブに移動して接続します。その後、キャラクター カードを選択するだけです。(
--enable-modules=classify,talkinghead --talkinghead-gpuサーバーを開始します。py)次に、キャラクター式を選択します。イメージ タイプ talkingheadボックスをチェックすると、スクリプトは現在のキャラクター式を
YOUR EXT URL:PORT/api/talkinghead/result_feedの結果に置き換え、ボックスをオフにすることで元のイメージに戻るはずですが、場合によっては新しいメッセージを送信して"再読み込み"イメージが必要です。キャラクター ディレクトリにtalkinghead.pngファイルがない場合、デフォルト イメージまたはtalkinghead.pngファイルを持つ最後のキャラクター カードが表示されます。アニメーション ソース イメージはキャラクター カードが変更される場合に変更。
次に、キャラクター式を開き、talkingheadイメージまでスクロールダウンし、以下の"制約条件入力イメージ"セクションの要件を満たしたイメージファイルをアップロード。
その後、talkingheadボックスをチェック/オフにしてキャラクター再読み込みします。イメージが奇妙に見える場合、透明/アルファレイヤーがない可能性が高い。その他、指示とテンプレートに従ってください。
#
入力イメージの制約条件
システムが適切に機能するには、入力イメージは次の制約に従う必要があります:
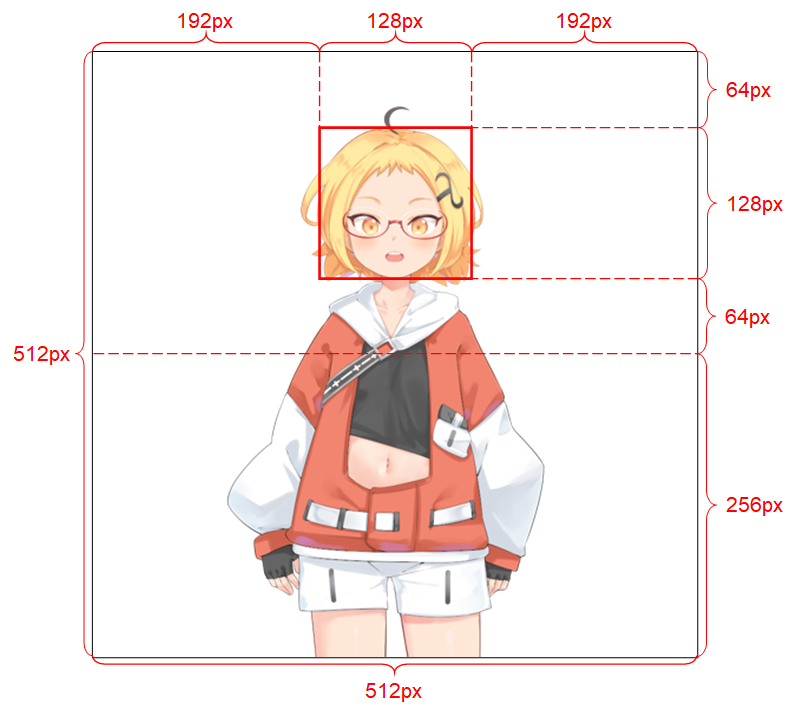
それは512 x 512の解像度であるべき。(プログラムが別のサイズの入力イメージを受け取った場合、イメージをこの解像度にサイズ変更し、この解像度で出力) アルファ チャネルが必要。 1人の人型キャラクターのみが含まれる必要があります。 キャラクターは直立し、前方を向いていることがべきです。 キャラクターの手は、の下で、頭から遠く離れるべき。 キャラクターの頭部は、イメージの上半分の中央にある128 x 128ボックスにほぼ含まれるべき。 キャラクターに属さないすべてのピクセル(すなわち背景ピクセル)のアルファ チャネルは0である必要があります。
#
高度なセクション
#
Python環境
基本機能(app.py)に加えて、manual_poserおよびifacialmocap_puppeteerの両方はデスクトップアプリケーションとして利用可能。それらを実行するには、Python言語で書かれたプログラムを実行するための環境をセットアップする必要があります。環境には次のソフトウェア パッケージが必要:
- Python >= 3.8
- PyTorch >= 1.11.0(CUDAサポート付き)
- SciPY >= 1.7.3
- wxPython >= 4.1.1
- Matplotlib >= 3.5.1
1つの方法はAnacondaをインストールしてシェルで次のコマンドを実行:
conda create -n talking-head-anime-3-demo python=3.8 conda activate talking-head-anime-3-demo conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch conda install scipy pip install wxpython conda install matplotlib
#
追加ブレンド モデル
含まれているのは1つ(最軽量)モデルのみです。追加のブレンド モデルをしたい場合は、モデル ファイルをhttps://www.dropbox.com/s/y7b8jl4n2euv8xe/talking-head-anime-3-models.zip?dl=0からダウンロードしてSillyTavern-extras\talkinghead\tha3\modelsフォルダーに解凍する必要があります。最終的には、dataフォルダーは次のようになります:
- tha3
- models
- separable_float
- editor.pt
- eyebrow_decomposer.pt
- eyebrow_morphing_combiner.pt
- face_morpher.pt
- two_algo_face_body_rotator.pt
- separable_half
-
- editor.pt
two_algo_face_body_rotator.pt
-
- standard_float
-
- editor.pt
two_algo_face_body_rotator.pt
-
- standard_half
-
- editor.pt
two_algo_face_body_rotator.pt
-
- separable_float
- models
モデル ファイルはクリエイティブ コモンズ Attribution 4.0国際ライセンスで配布されているため、商業用途に使用できます。ただし、Pramook Khungurn。Talking Head(?)アニメから単一の画像3:Now the Body Too。https://github.com/pkhungurn/talking-head-anime-3-demoが作成者。
#
Manual_poserデスクトップアプリケーション実行
シェルを開きます。リポジトリのルート ディレクトリに作業ディレクトリを変更。その後、実行:
python tha3/app/manual_poser.py コマンド実行の前、必要なパッケージを含むPython環境を有効化する必要があることに注意。
conda activate extras 環境をまだ有効化していない場合。